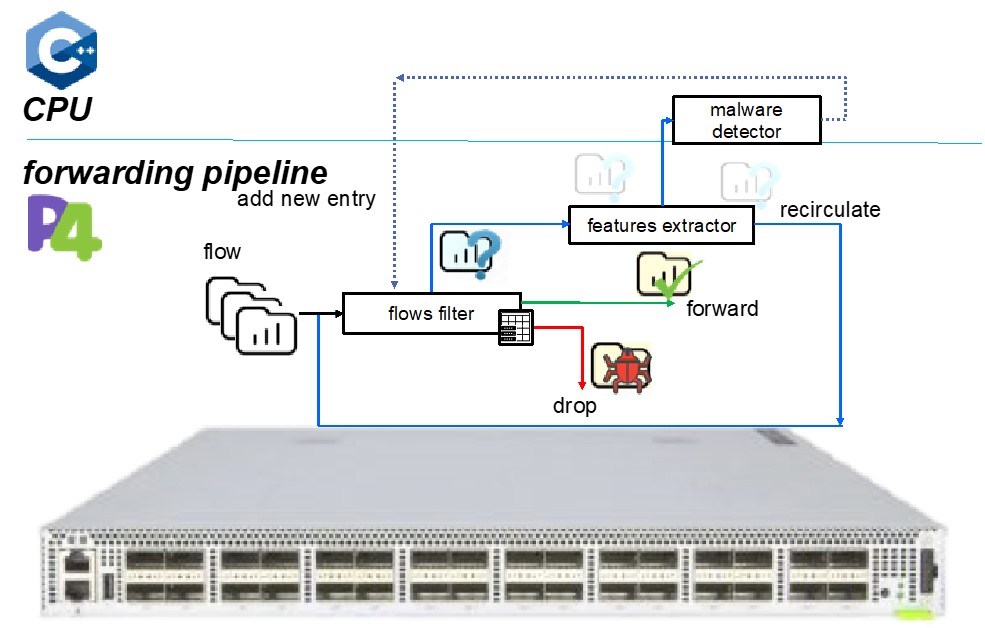
Motivation and Objective
In this work, we exploit NATs and propose a multi-level hierarchical NAT scheme to protect and enhance the security of a private network. We have implemented NAT in P4 hardware switches and cascaded them together so that protected hosts can hide behind multi-level NATs. Based on the mechanism of NAT, our scheme can prevent adversaries on the Internet from directly accessing the hosts in a private network unless they compromise all of the NATs in the hierarchy
Implementation
We have implemented both a software-based NAT scheme and a hardware-based NAT scheme. We configured the Netfilter with iptables on a Linux Ubuntu 18.04 machine as a software-based NAT. We implemented a hardware-based NAT in a P4 hardware switch, and there are two versions of it — static and dynamic versions. In the static version, we installed predefined entries into the NAT table. However, in the dynamic version, we executed a local controller on the P4 hardware switch. It would dynamically install entries into the NAT table when detecting the first packet of a new outbound flow.
Experimental Setup
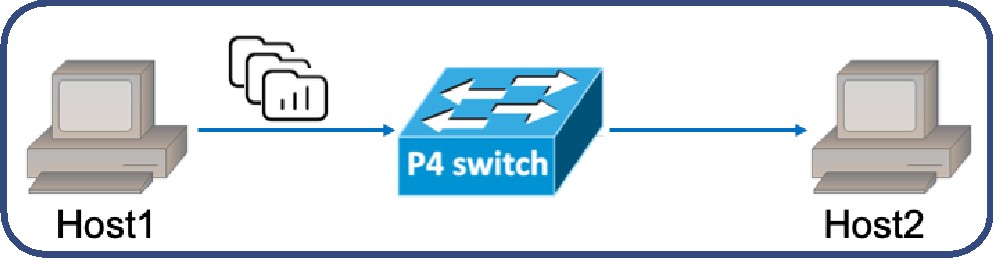
There are two scenarios for evaluation. In Fig. 1 (top), each host is behind a 2-level NAT scheme. We used iPerf to confirm functionality. In Fig. 1 (bottom), the client host is on the left and behind an N-level NAT scheme, where N can be 1, 2, 3, or 4. We used iPerf, curl, and ping to evaluate the performance. We also used a simple Python program to test the stability of our scheme. In all of the topologies used for experiments, the bandwidth of every link is 10 Gbps, and the length of every link is 1 meter.
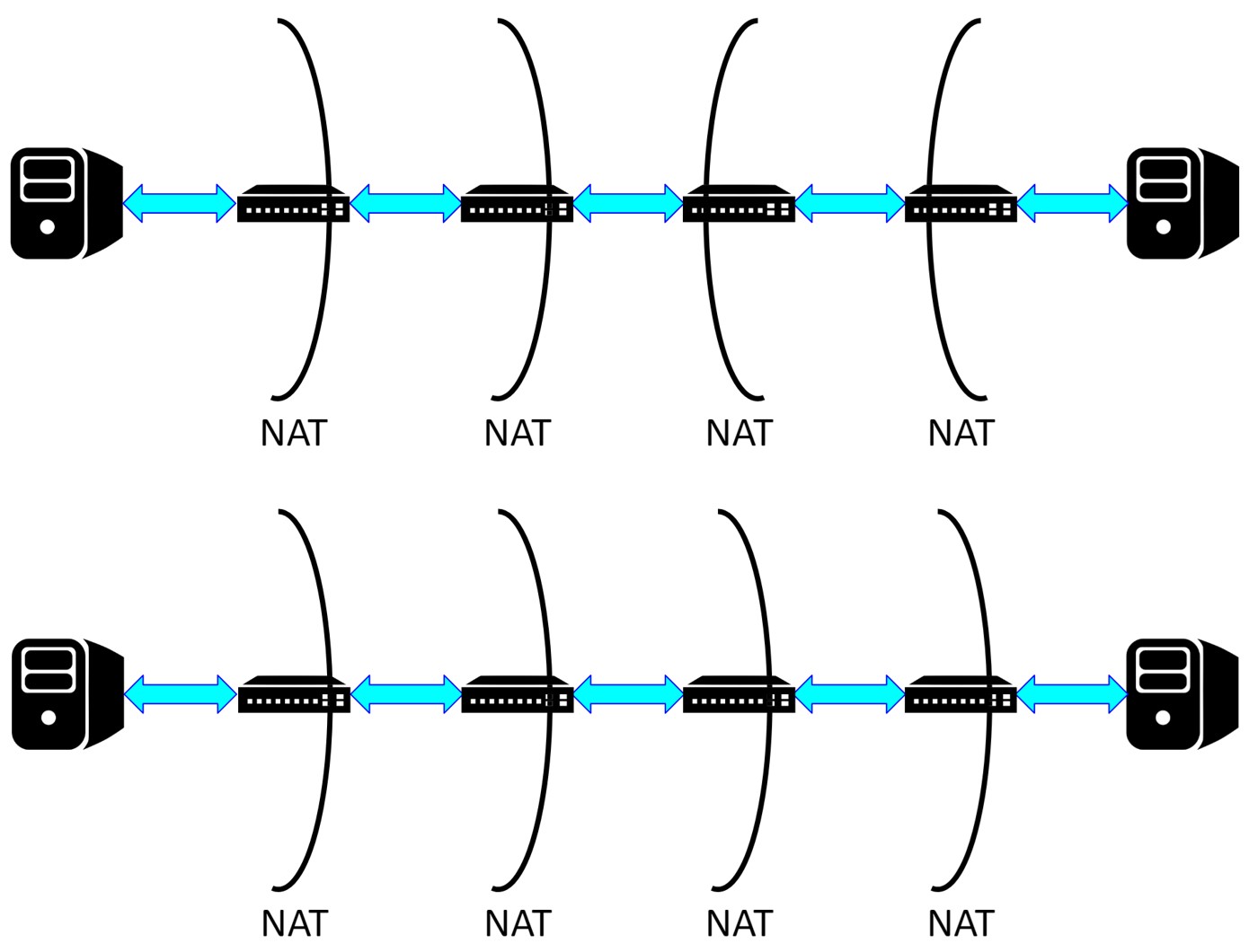
Fig.1: The Experiment Topologies
Evaluation
In the functionality test, experimental results confirm that our schemes can function correctly.
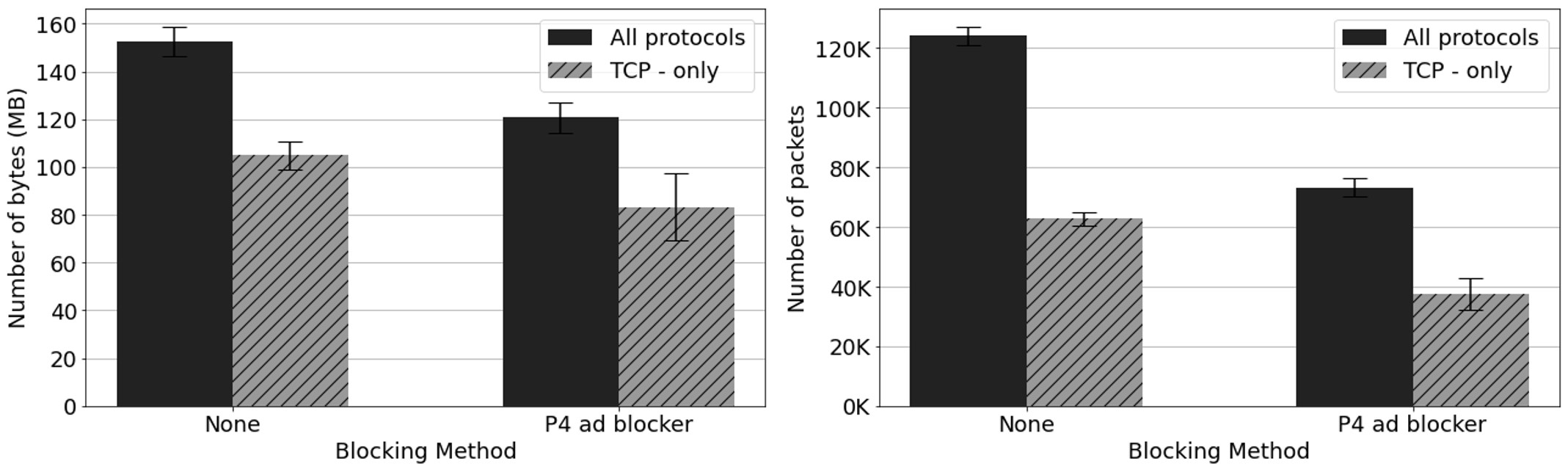
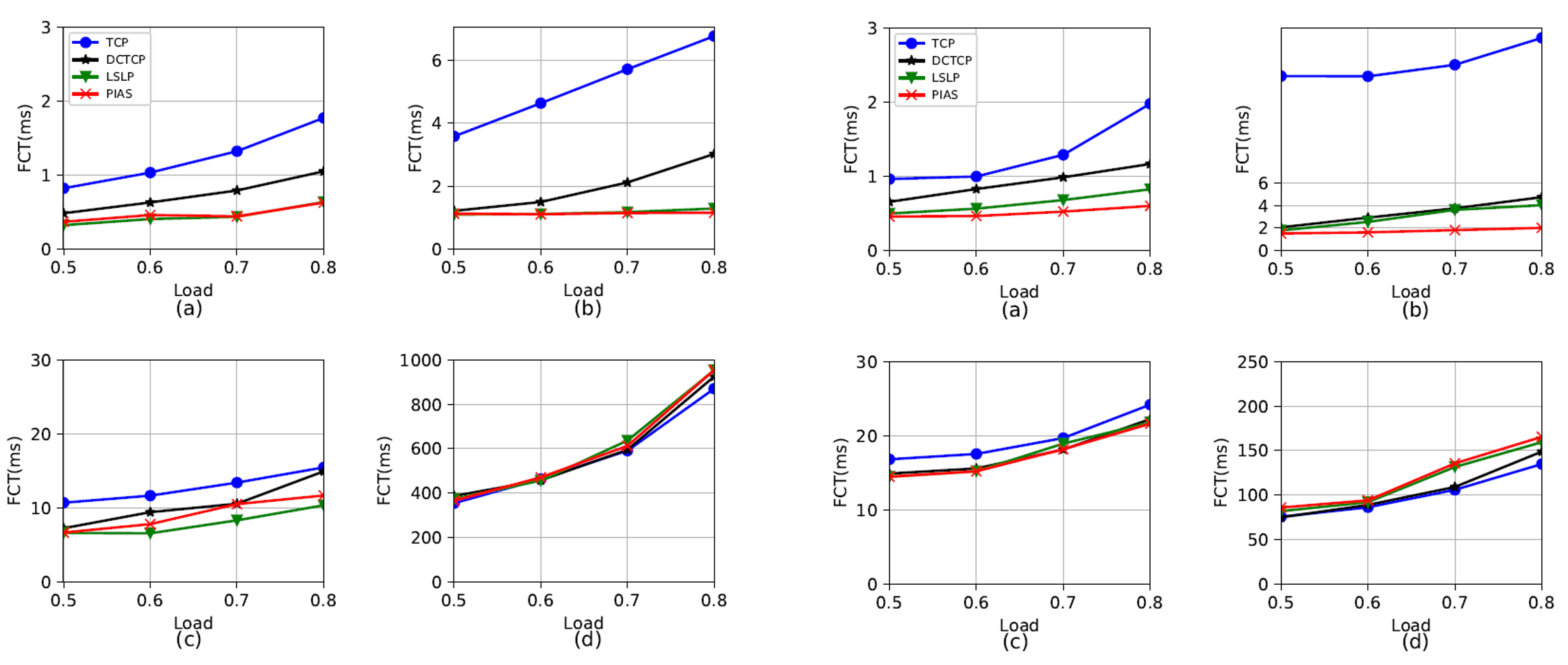
In Fig. 2 (left), the throughput of software-based NAT gradually declines as the number of hops (i.e., the value of N) increases. However, the throughput of the hardware-based NAT is not affected. In Fig. 2 (right), the latency of dynamic hardware-based NAT increases with the number of hops and is higher than the other two schemes.
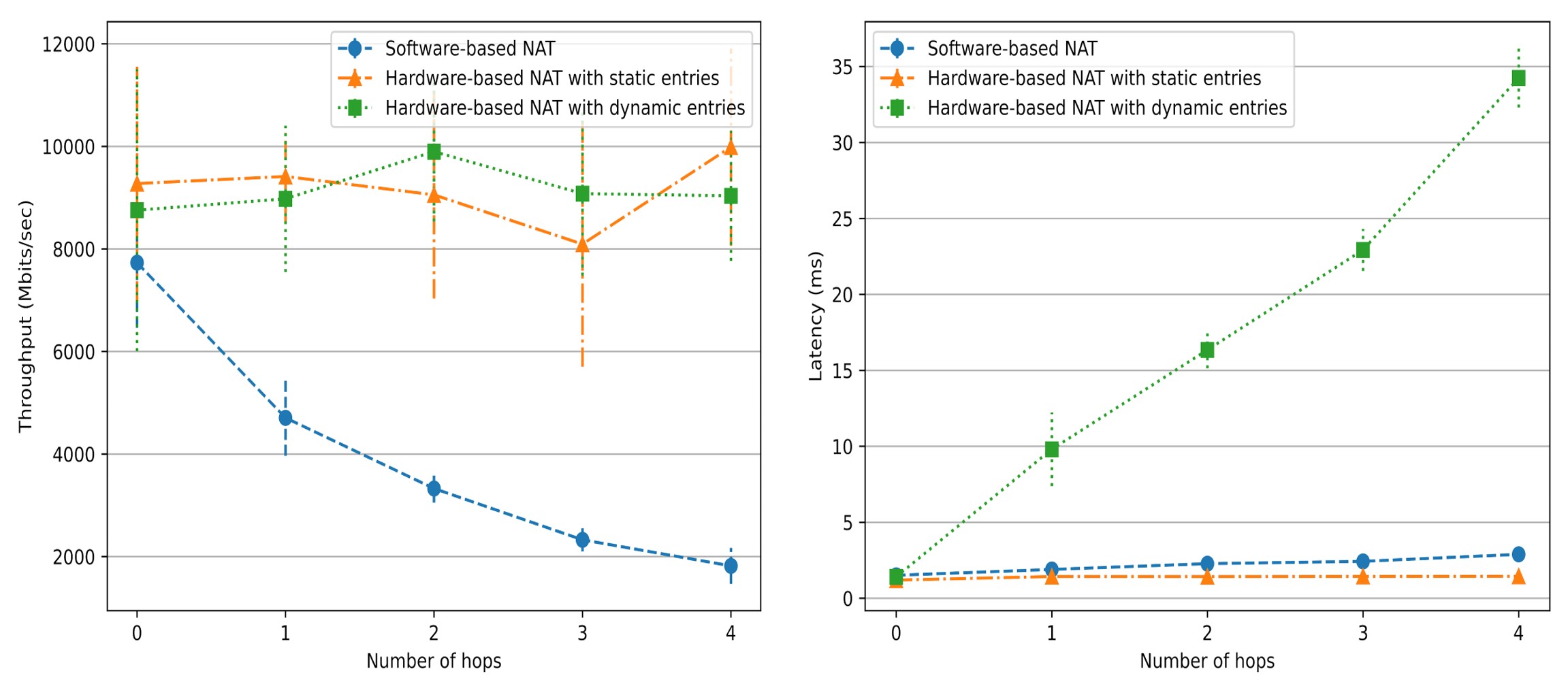
Fig.2: iPerf and curl testing results
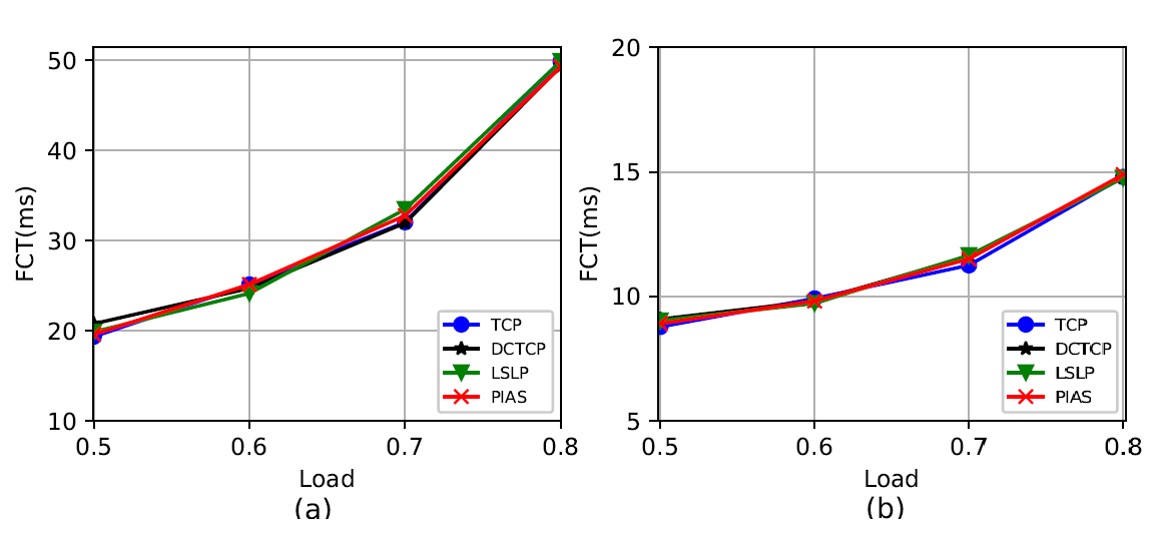
In Fig. 3 (left), the latency of software-based NAT linearly rises as the number of hops increases. However, the latency of static hardware-based NAT is not affected. To get insights into the phenomenon in Fig. 2 (right), we used ping to measure the latency of the first few packets of a new outbound flow. In Fig. 3 (right), except for the first ping packet, the latency of all subsequent ping packets dropped to only 0.1x milliseconds. This means that our simplified controller is the primary reason for the large latency of dynamic hardware-basde NAT.
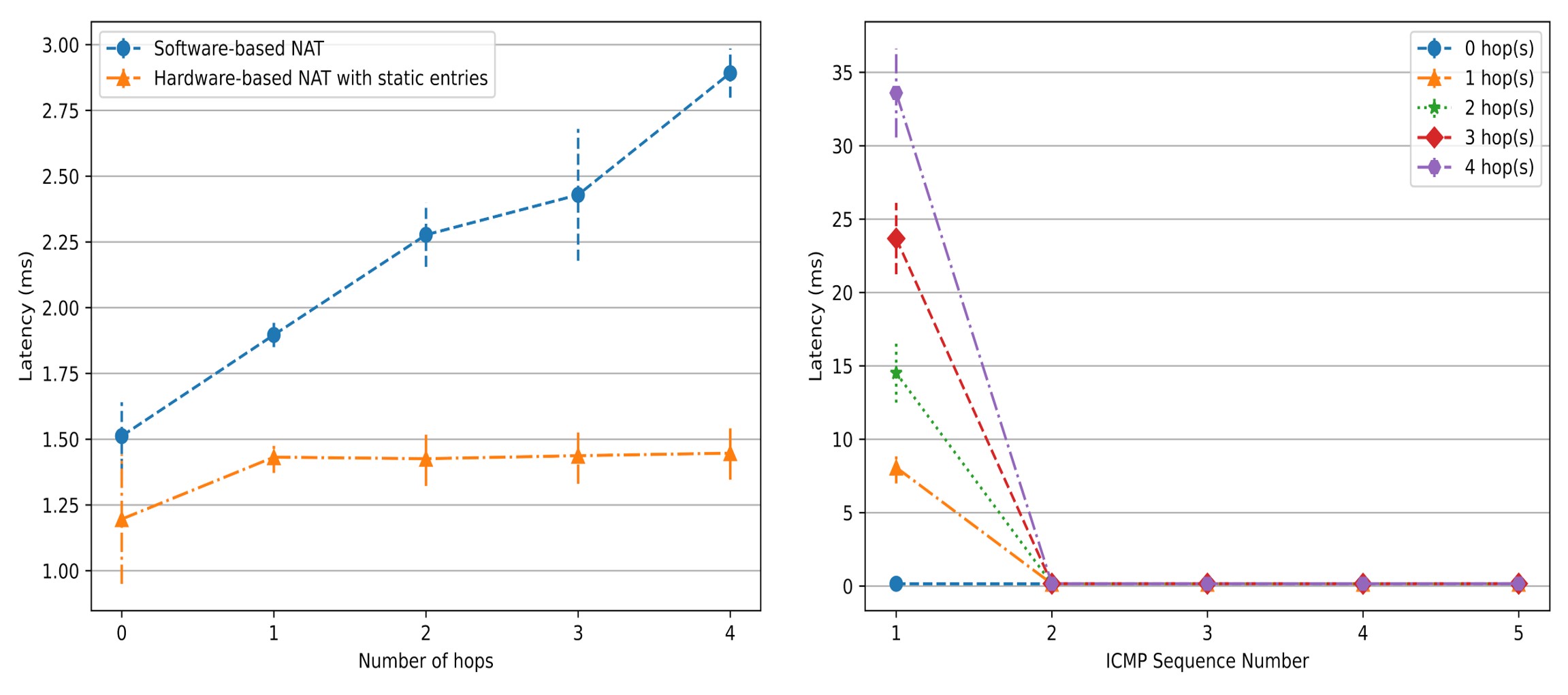
Fig. 3: curl and ping testing results
After the 3-hour test, all connections initiated from the client host are finished successfully. This result shows that our dynamic hardware-based NAT scheme can operate stably under high load.
Video Link: https://youtu.be/KvD2ju0bCrE